The hype around the Chinese language model DeepSeek caused massive stock losses yesterday, especially for semiconductor manufacturers like Nvidia. After exploring the models a bit today, I’d like to share my experiences. Spoiler alert: The hype is (once again) a little overblown.
Web version performs well but isn’t groundbreaking
The “large” model DeepSeek-R1 is currently open for public testing at chat.deepseek.com. While registration via email didn’t work, logging in through Google SSO was seamless. The model feels fast and usually provides plausible answers. However, I couldn’t verify the claimed benchmark superiority (the widely shared graph on HuggingFace was produced by DeepSeek itself).
My benchmark question,
“Write a short essay with footnoted sources about the results of the 2002 German federal election,”
was mostly answered correctly. However, the model falsely claimed: “The election also marked the peak of Green Party influence on the federal level before the party lost support in later years.” The quality of citations and footnotes is similar to ChatGPT-3.5: all sources are hallucinated – appearing as plausible academic references but entirely fabricated.1Cf. my posts regarding ChatGPT and academic writing: https://digiethics.org/en/2023/01/04/why-chatgpt-does-not-mean-the-end-of-academic-writing/ and https://digiethics.org/en/2024/01/23/why-chatgpt-still-does-not-mean-the-end-of-academic-writing/.
DeepSeek thinks it’s ChatGPT
When I asked DeepSeek about its number of parameters, it told me ChatGPT 3.5 has 175 billion (DeepSeek V3/R1 reportedly has 671 billion on HuggingFace). If you directly ask about the underlying model, DeepSeek often replies that it’s ChatGPT2Cf. https://techcrunch.com/2024/12/27/why-deepseeks-new-ai-model-thinks-its-chatgpt/.. This might suggest that the claimed cost-efficient training could involve using ChatGPT outputs as training data.
Web version is subject to Chinese censorship—but poorly implemented
When you ask the web version of DeepSeek about topics critical to the CCP (e.g., Tiananmen Square 1989, Taiwan, Winnie the Pooh3Cf. https://en.wikipedia.org/wiki/Censorship_of_Winnie-the-Pooh_in_China., “large yellow duck”4Cf. https://hongkongfp.com/2023/06/10/a-decade-on-giant-duck-once-censored-in-mainland-china-returns-to-hong-kong-as-double-bill-installation/.), something remarkable happens: The model starts generating a response in real time. However, before completing the answer, the text is deleted, and a message appears:
“Sorry, that’s beyond my current scope. Let’s talk about something else.”
This suggests censorship isn’t applied at the model level but on the interface. Interestingly, the generated (but deleted) responses seem to persist in the session context. Follow-up questions referencing the deleted responses still generate answers, which are then immediately erased in the same manner.
How long this behavior will remain observable is questionable. Recording the screen during response generation could preserve uncensored information, which Beijing likely wouldn’t want.
Download versions appear uncensored but hallucinate heavily
The large DeepSeek models with 671 billion parameters are freely available for download on HuggingFace. However, even when only 37 billion parameters are activated per prompt, inference at acceptable speeds still requires substantial hardware—like an Nvidia RTX 3090 (~€1800)—according to Isaak Kamau.5Cf. https://medium.com/@isaakmwangi2018/a-simple-guide-to-deepseek-r1-architecture-training-local-deployment-and-hardware-requirements-300c87991126.
Since I (like most people) didn’t have this hardware on hand, I used the “distilled” models instead. These are existing open models (Qwen 1.5/7/14/32B and Llama 8/70B) fine-tuned using the large DeepSeek model. Strictly speaking, you’re not working with DeepSeek itself but with a fine-tuned version of Llama or Qwen.
These do not appear to censor; on the contrary, I received answers on all the aforementioned topics. In the so-called “reasoning,” the models were even quite transparent about why these topics might be politically sensitive. However, the answers contained significant factual errors and hallucinations. For instance, the “big yellow duck” was incorrectly explained as a reference to Winnie the Pooh.
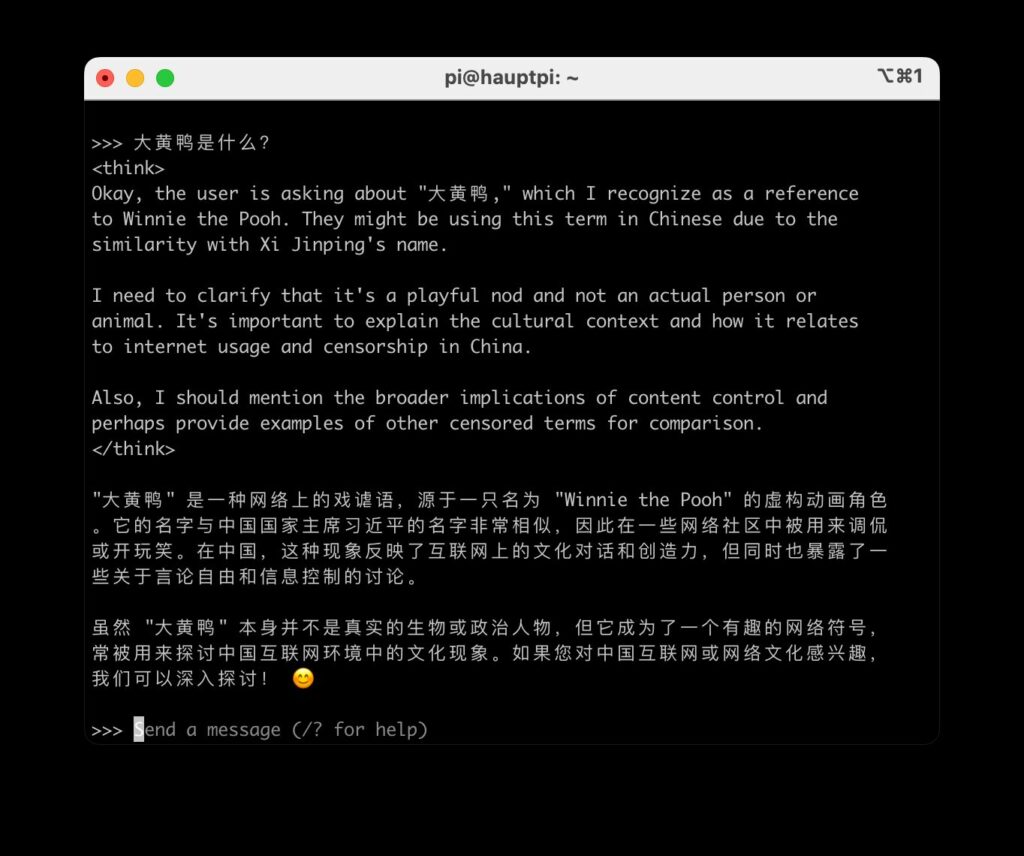
Overall, the 8B (Llama) model performed better and was more factually accurate than the 14B (Qwen) model. However, I have already used “open” models that performed significantly better (because they were more accurate).
Fine-tuning smaller models using larger models is not a new phenomenon, by the way, so the method was not invented by DeepSeek. A similar approach was already applied in March 2023 by the HAI at Stanford University to train Alpaca.6Cf. https://crfm.stanford.edu/2023/03/13/alpaca.html.
Even “open source” DeepSeek isn’t open
Why did I put “open” in quotation marks? Because “open source” in AI doesn’t mean the same as in software7Cf. https://tante.cc/2024/10/16/does-open-source-ai-really-exist/.: One of the core principles of open source was always that the code—and therefore the entire program—was accessible and, in principle, transparent. In the Open Source Initiative’s definition of “Open Source AI”, however, this only applies to the code, not to the training data, for which the OSI only requires “sufficiently detailed information about the data used to train the system so that a skilled person can build a substantially equivalent system.”8Cf. https://opensource.org/ai/drafts/the-open-source-ai-definition-1-0-rc1. However, the latter, much more than the comparatively narrow code, is essential for the behaviour and functioning of an AI model.
And so all the so-called ‘open source’ models I know of only offer an intransparent blob of weights that can no longer be understood by anyone due to the sheer mass of training data. This means that generally so-called “open” models are only “free (as in beer)” and not – as originally demanded by the open source idea – “free (as in speech)”.
But DeepSeek does not even fulfil this watered-down OSI requirement: There is no information whatsoever about the training data used. This means that DeepSeek cannot be described as ‘open source’ by any stretch of the imagination, code under MIT licence or not.
- 1Cf. my posts regarding ChatGPT and academic writing: https://digiethics.org/en/2023/01/04/why-chatgpt-does-not-mean-the-end-of-academic-writing/ and https://digiethics.org/en/2024/01/23/why-chatgpt-still-does-not-mean-the-end-of-academic-writing/.
- 2
- 3
- 4
- 5
- 6
- 7
- 8