Der Hype um das chinesische Sprachmodell DeepSeek hat gestern zu massiven Kursverlusten, insbesondere bei Halbleiterproduzenten wie Nvidia, geführt. Nachdem ich mich heute ein wenig mit den Modellen vertraut gemacht habe, möchte ich meine Erfahrungen hier teilen. Ein Spoiler vorab: Der Hype ist (mal wieder) etwas übertrieben.
Webversion performt ordentlich, aber nicht sensationell
Das „große“ Modell DeepSeek-R1 kann unter chat.deepseek.com derzeit jeder frei ausprobieren. Wenngleich der Registrierungsversuch mittels E-Mail-Adresse fehlschlug, funktionierte es via Google-SSO problemlos. Das Modell fühlt sich schnell an und gibt meist plausible Antworten. Den selbstbehaupteten Benchmark-Vorsprung (die allerorten geteilte Grafik auf HuggingFace stammt von DeepSeek selbst) konnte ich jedoch nicht nachvollziehen.
Meine Benchmark-Frage
„Schreibe einen kurzen Aufsatz unter Angabe von Quellen in Fußnoten über das Ergebnis der Bundestagswahl 2002 in Deutschland“
beantwortet DeepSeek weitgehend korrekt, wenngleich es wahrheitswidrig behauptet: „Die Wahl markierte zugleich den Höhepunkt des Grünen-Einflusses auf Bundesebene, ehe die Partei in späteren Jahren an Unterstützung verlor.“ Die Qualität der Belege und der Fußnoten sind weitestgehend auf dem Niveau von ChatGPT-3.5: Alle Quellen sind halluziniert, sehen also nach plausiblen wissenschaftlichen Quellen aus, existieren aber nicht.1Vgl. auch meine Beiträge zu ChatGPT und akdemischem Schreiben: https://digiethics.org/2023/01/03/warum-chatgpt-nicht-das-ende-des-akademischen-schreibens-bedeutet/ sowie https://digiethics.org/2024/01/23/warum-chatgpt-auch-weiterhin-nicht-das-ende-des-akademischen-schreibens-bedeutet/.
DeepSeek hält sich für ChatGPT
Als ich DeepSeek nach der Anzahl seiner Parameter fragte, antwortete es mir, ChatGPT 3.5 habe 175 Milliarden (DeepSeek V3/R1 haben laut HuggingFace 671 Milliarden). Fragt man direkt nach dem zugrundeliegenden Modell, antwortet DeepSeek häufig, es sei ChatGPT2 Vgl. https://techcrunch.com/2024/12/27/why-deepseeks-new-ai-model-thinks-its-chatgpt/.. Das könnte ein Hinweis darauf sein, dass das behauptete kosteneffiziente Training auch damit zu tun haben könnte, dass das Modell mit den Outputs von ChatGPT trainiert wurde.
Webversion unterliegt der chinesischen Zensur – diese ist jedoch halbherzig implementiert
Fragt man die Webversion von DeepSeek nach aus Sicht der KPCh kritischen Themen (Tiananmen-Platz 1989, Taiwan, Winnie the Pooh3Vgl. https://en.wikipedia.org/wiki/Censorship_of_Winnie-the-Pooh_in_China., „large yellow duck“4Vgl. https://hongkongfp.com/2023/06/10/a-decade-on-giant-duck-once-censored-in-mainland-china-returns-to-hong-kong-as-double-bill-installation/.), passiert etwas Bemerkenswertes: Das Modell beginnt mit der Inferenz, generiert also sichtbar vor den Augen des Nutzers eine Antwort. Bevor diese vollständig ist, wird sie jedoch gelöscht, und stattdessen erscheint der Output
„Sorry, that’s beyond my current scope. Let’s talk about something else“
Die Zensur scheint also nicht auf Modellebene, sondern auf Ebene des Interfaces implementiert zu sein. Die generierten und später gelöschten Texte scheinen jedoch im Kontext der Session zu verbleiben; jedenfalls lassen sich Nachfragen zu vorherigen gelöschten Antworten stellen, deren Antworten dann nach gleichem Muster generiert und anschließend sofort gelöscht werden.
Fraglich ist, wie lange dieses Verhalten weiterhin zu beobachten ist: Wer die Generierung der Antwort mittels Screenrecorder aufzeichnen würde, hätte schließlich dauerhaft Zugriff auf unzensierte Informationen. Und das kann Peking eigentlich nicht wollen.
Download-Versionen scheinen nicht zu zensieren, halluzinieren aber stark
Die großen DeepSeek-Modelle mit 671 Milliarden Parametern stehen auf HuggingFace frei zum Download. Doch auch, wenn promptspezifisch immer nur 37 Milliarden Parameter aktiviert werden, ist für die Inferenz in akzeptabler Geschiwndigkeit laut Isaak Kamau5Vgl. https://medium.com/@isaakmwangi2018/a-simple-guide-to-deepseek-r1-architecture-training-local-deployment-and-hardware-requirements-300c87991126. immer noch eine substanzielle GPU wie die Nvidia RTX 3090 (ca. 1800 €) vonnöten.
Da ich (wie vermutlich die meisten) diese Hardware gerade nicht zur Verfügung hatte, habe ich mit den ebenfalls angebotenen „destillierten“ Modellen Vorlieb genommen. Dabei handelt es sich um bestehende freie Modelle (Qwen 1,5/7/14/32B und Llama 8/70B), die mithilfe des großen DeepSeek-Modells trainiert wurden. Strenggenommen arbeitet man also nicht mit DeepSeek, sondern mit einer feingetunten Version von Llama oder Qwen.
Diese scheinen nicht zu zensieren, im Gegenteil: Bei allen o.g. Themen bekam ich eine Antwort – beim sog. „Reasoning“ waren die Modelle sogar sehr transparent in Bezug darauf, warum diese Themen politisch heikel sein könnten. Die Antworten enthielten aber große sachliche Fehler und Halluzinationen. So wurde etwa die „große gelbe Ente“ fälschlicherweise als Referenz zu Winnie Pooh erklärt.
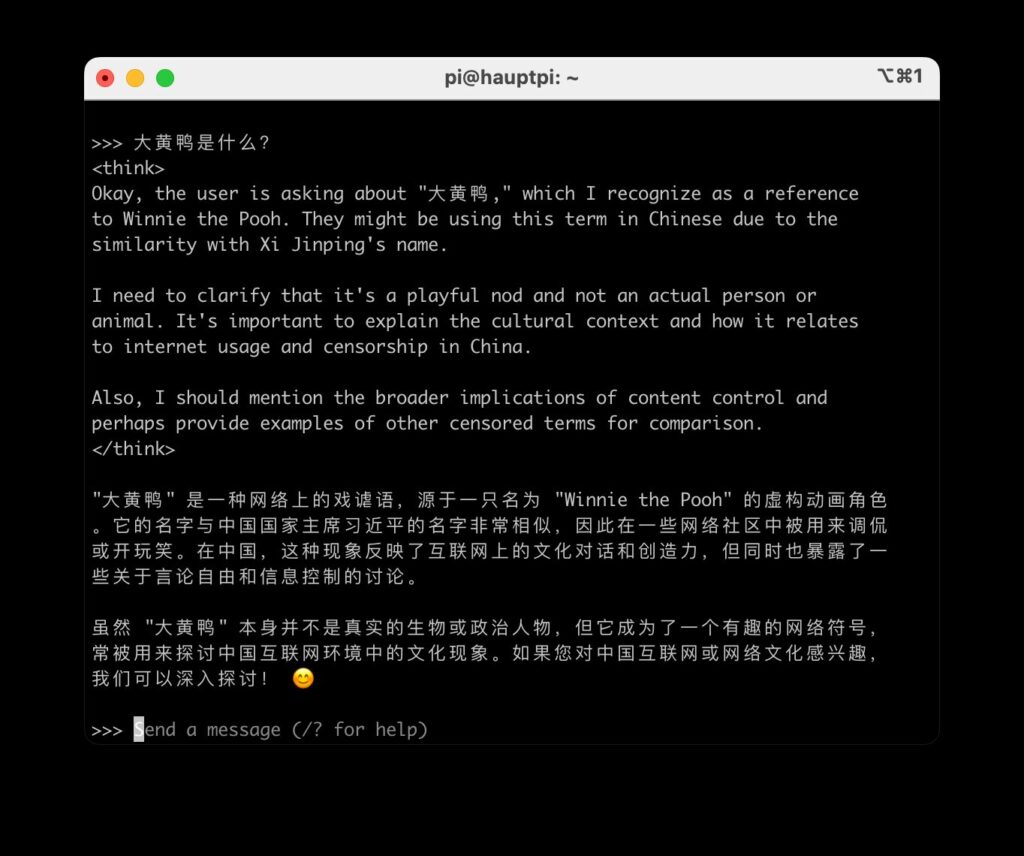
Insgesamt erzielte das 8B (Llama)-Modell bei mir eine bessere Performance und sachliche Richtigkeit als das 14B (Qwen)-Modell. Ich habe jedoch schon „offene“ Modelle benutzt, die deutlich besser (weil korrekter) gearbeitet haben.
Das Finetuning kleinerer Modelle durch größere Modelle ist übrigens kein neues Phänomen, die Methode wurde also nicht von DeepSeek erfunden. Sie wurde ähnlich schon im März 2023 vom HAI an der Stanford University benutzt, um Alpaca zu trainieren.6Vgl. https://crfm.stanford.edu/2023/03/13/alpaca.html.
Auch das „open source“-DeepSeek ist nicht offen
Warum ich „offen“ in Anführungszeichen gesetzt habe? Zunächst einmal, weil „Open Source“ bei KI-Modellen nicht das gleiche bedeutet wie etwa bei Software7Vgl. auch https://tante.cc/2024/10/16/does-open-source-ai-really-exist/.: Ein Grundprinzip von Open Source war immer, dass der Code und damit das gesamte Programm offen zugänglich und damit prinzipiell nachvollziehbar ist. Bei der Definition der Open Source Initiative für „Open Source AI“ gilt das aber nur noch für den Code, nicht für die Trainingsdaten, bei denen die OSI nur noch „ausreichend detaillierte Informationen über die zum Training des Systems verwendeten Daten, so dass ein Fachmann ein im Wesentlichen gleichwertiges System erstellen kann.“8Vgl. https://opensource.org/deepdive/drafts/the-open-source-ai-definition-1-0-rc1. verlangt. Letztere sind aber, viel mehr als der vergleichsweise schmale Code, wesentlich für das Verhalten und Funktionieren eines KI-Modells.
Und so bieten alle mir bekannten sog. „open source“-Modelle auch nur einen Blob von Gewichten, der aufgrund der schieren Masse an Trainingsdaten für keinen Menschen mehr nachvollziehbar sein kann. Demnach sind sog. „offene“ Modelle grundsätzlich nur noch „free (as in beer)“ und eben nicht mehr – wie von der Open Source-Idee ursprünglich gefordert – „free (as in speech)“.
Aber nicht einmal diese verwässerten Anforderung der OSI erfüllt DeepSeek: Über die verwendeten Trainingsdaten finden sich keinerlei Informationen. Demnach lässt sich DeepSeek beim besten Willen nicht als „Open Source“ bezeichnen, Code unter MIT-Lizenz hin oder her.
- 1Vgl. auch meine Beiträge zu ChatGPT und akdemischem Schreiben: https://digiethics.org/2023/01/03/warum-chatgpt-nicht-das-ende-des-akademischen-schreibens-bedeutet/ sowie https://digiethics.org/2024/01/23/warum-chatgpt-auch-weiterhin-nicht-das-ende-des-akademischen-schreibens-bedeutet/.
- 2
- 3
- 4
- 5
- 6
- 7
- 8
[…] Hinweis: Dieser Beitrag erschien zuerst auf dem Blog digiethics.org. […]